Сложные объявления
Иногда Си ругают за синтаксис объявлений, особенно тех, которые содержат в себе указатели на функции. Таким синтаксис получился в результате нашей попытки сделать похожими объявления объектов и их использование. В простых случаях этот синтаксис хорош, однако в сложных ситуациях он вызывает затруднения, поскольку объявления перенасыщены скобками и их невозможно читать слева направо. Проблему иллюстрирует различие следующих двух объявлений:
int *f(); /* f: функция, возвращающая ук-ль на int */ int (*pf)(); /* pf: ук-ль на ф-цию, возвращающую int */
Приоритет префиксного оператора * ниже, чем приоритет (), поэтому во втором случае скобки необходимы.
Хотя на практике по-настоящему сложные объявления встречаются редко, все же важно знать, как их понимать, а если потребуется, и как их конструировать. Укажем хороший способ: объявления можно синтезировать, двигаясь небольшими шагами с помощью typedef, этот способ рассмотрен в . В настоящем параграфе на примере двух программ, осуществляющих преобразования правильных Си-объявлений в соответствующие им словесные описания и обратно, мы демонстрируем иной способ конструирования объявлений. Словесное описание читается слева направо.
Первая программа, dcl, - более сложная. Она преобразует Си-объявления в словесные описания так, как показано в следующих примерах:
char **argv argv: указ. на указ. на char int (*daytab)[13] daytab: указ. на массив[13] из int int (*daytab)[13] daytab: массив[13] из указ. на int void *comp() comp: функц. возвр. указ. на void void (*comp)() comp: указ. на функц. возвр. void char (*(*x())[])() x: функц. возвр. указ. на массив[] из указ. на функц. возвр. char char(*(*x[3])())[5] x: массив[3] из указ. на функц. возвр. указ. на массив[5] из char
Функция dcl в своей работе использует грамматику, специфицирующую объявитель. Эта грамматика строго изложена в приложения A, а в упрощенном виде записывается так:
объявитель: необязательные * собственно-объявитель
собственно-объявитель: имя
(объявитель) собственно-объявитель() собственно-объявитель [необязательный размер]
Говоря простым языком, объявитель есть собственно-объявитель, перед которым может стоять * (т. е. одна или несколько звездочек), где собственно- объявитель есть имя, или объявитель в скобках, или собственно-объявитель с последующей парой скобок, или собственно-объявитель с последующей парой квадратных скобок, внутри которых может быть помещен размер.
Эту грамматику можно использовать для грамматического разбора объявлений. Рассмотрим, например, такой объявитель:
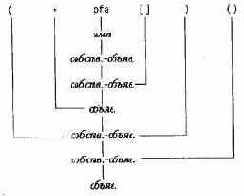
(*pfa[])()
Имя pfa будет классифицировано как имя и, следовательно, как собственно- объявитель. Затем pfa[] будет распознано как собственно-объявитель, а *pfa[] - как объявитель и, следовательно, (*pfa[]) есть собственно-объявитель. Далее, (*pfa[])() есть собственно-объявитель и, таким образом, объявитель. Этот грамматический разбор можно проиллюстрировать деревом разбора, приведенным на следующей странице (где собственно-объявитель обозначен более коротко, а именно собств.-объяв.).
Сердцевиной программы обработки объявителя является пара функций dcl и dirdcl, осуществляющих грамматический разбор объявления согласно приведенной грамматике. Поскольку грамматика определена рекурсивно, эти функции обращаются друг к другу рекурсивно, по мере распознавания отдельных частей объявления. Метод, примененный в обсуждаемой программе для грамматического разбора, называется рекурсивным спуском.
/* dcl: разбор объявителя */ void dcl(void) { int ns;
for (ns = 0, gettoken() == '*';) /* подсчет звездочек */ ns++;
dirdcl(); while(ns-- > 0) strcat(out, "указ. на”); }
/* dirdcl: разбор собственно объявителя */ void dirdcl(void) { int type;
if (tokentype == '(') { dcl(); if (tokentype != ')') printf("oшибкa: пропущена )\n"); } else if (tokentype == NAME) /* имя переменной */ strcpy(name, token); else printf("ошибка: должно быть name или (dcl)\n");
while((type = gettoken()) == PARENS type == BRACKETS) if (type == PARENS) strcat(out, "функц. возвр."); else { strcat(out, " массив"); strcat(out, token); strcat(out, " из"); } }
Приведенные программы служат только иллюстративным целям и не вполне надежны. Что касается dcl, то ее возможности существенно ограничены. Она может работать только с простыми типами вроде char и int и не справляется с типами аргументов в функциях и с квалификаторами вроде const. Лишние пробелы для нее опасны. Она не предпринимает никаких мер по выходу из ошибочной ситуации, и поэтому неправильные описания также ей противопоказаны. Устранение этих недостатков мы оставляем для упражнений. Ниже приведены глобальные переменные и главная программа main.
#include <stdio.h> #include <string.h> #include <ctype.h>
#define MAXTOKEN 100
enum {NAME, PARENS, BRACKETS};
void dcl(void); void dirdcl(void);
int gettoken(void); int tokentype; /* тип последней лексемы */ char token[MAXTOKEN]; /* текст последней лексемы */ char name[MAXTOKEN]; /* имя */ char datatype[MAXTOKEN]; /* тип = char, int и т.д. */ char out[1000]; /* выдаваемый текст */
main() /* преобразование объявления в словесное описание */ { while (gettoken() != EOF) { /* 1-я лексема в строке */ strcpy(datatype, token); /* это тип данных */ out[0] = '\0'; dcl(); /* разбор остальной части строки */ if (tokentype != '\n') printf("синтаксическая ошибка\n"); printf("%s: %s %s\n", name, out, datatype); } return 0; }
Функция gettoken пропускает пробелы и табуляции и затем получает следующую лексему из ввода: "лексема" (token) - это имя, или пара круглых скобок, или пара квадратных скобок (быть может, с помещенным в них числом), или любой другой единичный символ.
int gettoken(void) /* возвращает следующую лексему */ { int с, getch(void); void ungetch(int); char *p = token;
while ((c = getch()) == ' ' с = '\t') ; if (c == '(') { if ((c = getch())== ')' { strcpy(token, "()"); return tokentype = PARENS; } else { ungetch(c); return tokentype = '('; } } else if (c == '['){ for (*p++ = c; (*p++ = getch()) != ']'; ) ; *p = '\0'; return tokentype = BRACKETS; } else if (isalpha(c)) { for (*p++ = c; isalnum(c = getch()); ) *p++ = c; *p = '\0'; ungetch(c); return tokentype = NAME; } else return tokentype = c; }
Функции getch и ungetch были рассмотрены в .
Обратное преобразование реализуется легче, особенно если не придавать значения тому, что будут генерироваться лишние скобки. Программа undcl превращает фразу вроде "x есть функция, возвращающая указатель на массив указателей на функции, возвращающие char", которую мы будем представлять в виде
х () * [] * () char
в объявление
char (*(*х())[])()
Такой сокращенный входной синтаксис позволяет повторно пользоваться функцией gettoken. Функция undcl использует те же самые внешние переменные, что и dcl.
/* undcl: преобразует словесное описание в объявление */ main() { int type; char temp[MAXTOKEN];
while (gettoken() != EOF) { strcpy(out, token); while ((type = gettoken()) != '\n') if (type == PARENS type == BRACKETS) strcat(out, token); else if (type == '*' ) { sprintf(temp, "(*%s)", out); strcpy(out, temp); } else if (type == NAME) { sprintf(temp, "%s %s", token, out); strcpy(out, temp); } else printf( "неверный элемент %s в фразе\n", token); printf("%s\n", out); } return 0; }
Упражнение 5.18. Видоизмените dcl таким образом, чтобы она обрабатывала ошибки во входной информации.
Упражнение 5.19. Модифицируйте undcl так, чтобы она не генерировала лишних скобок.
Упражнение 5.20. Расширьте возможности dcl, чтобы dcl обрабатывала объявления с типами аргументов функции, квалификаторами вроде const и т. п.
